Ground Truth

A neurologist sits across from a patient with Parkinson's disease. She watches him walk, examines his tremor, asks about his sleep, his mood, how he buttons his shirt. Then she assigns a number, a score on the Unified Parkinson's Disease Rating Scale, and that number becomes the ground truth for everything downstream: the primary endpoint of the trial, the training target for the model, the signal against which a drug's efficacy is judged. She is doing skilled work with the only instrument she has been given. The patient's biology is continuous, multidimensional, shifting by the hour. The number is a compression of that lived physiological state into an integer, mediated by training, fatigue, experience, and the fifteen minutes a clinic affords. The limitation is not the clinician. It is what we have asked her to use.
The phrase to pause on is "ground truth." In machine learning the ground truth is the target a model is trained to reproduce, and the assumption, rarely examined, is that the target is true. In clinical medicine it almost never is. What stands in its place is a convention, and most AI built for healthcare inherits that convention without examining it.
The convention
The rating scales, questionnaires, and diagnostic categories that serve as ground truth in healthcare were not derived from the biology they purport to measure. Many descend from nineteenth-century clinical observation, shaped by the diagnostic language available at the time, codified through decades of committee revision, and carried forward because replacing an entrenched instrument is harder than refining one. They are social and historical objects, layered with compromise. The diagnostic threshold for hypertension has been revised repeatedly, each revision reclassifying millions overnight with no change in anyone's physiology. Diabetes thresholds have moved the same way. The boundaries of major depressive disorder shift between editions of the DSM. These labels fail along two distinct axes: clinicians applying the same criteria to the same patient frequently disagree, a failure of reliability, and the categories themselves do not map cleanly onto the underlying biology, a failure of validity. The National Institute of Mental Health named the second failure when it launched its Research Domain Criteria initiative, turning away from categorical diagnosis toward dimensional, biology-grounded constructs, on the reasoning that the categories, however reliably applied, do not carve nature at its joints. Continuous biology is being cut into categories at thresholds that move, and every movement reveals the boundary was where a committee placed it, not where the biology demanded.
The same convention appears under different names depending on context. In a clinical trial it is called an endpoint. In a machine learning pipeline it is called a label. In a regulatory submission it is called a biomarker or a surrogate. In each case the object is the same: a compressed, categorical summary of a biological state that is none of those things. The question of whether this summary is faithful to the biology it represents is the same question regardless of what it is called, and it is the question most of the field declines to ask.
The inheritance
When a model is trained to predict disease progression, it is trained against these scores. The model learns the label, and the label carries within it every historical compromise and every threshold choice that shaped it. Random noise in a label averages out; more data and more parameters genuinely suppress it. Systematic error does not. A larger model trained on a contingent label does not transcend the label. It fits it more precisely, becoming confidently wrong in the exact shape of the artifact it was trained on. If the target is a lossy encoding of the biology, the ceiling of the model is the ceiling of the encoding. Parameters, data, and compute do not raise it; they sharpen the fit to the same flawed surface.
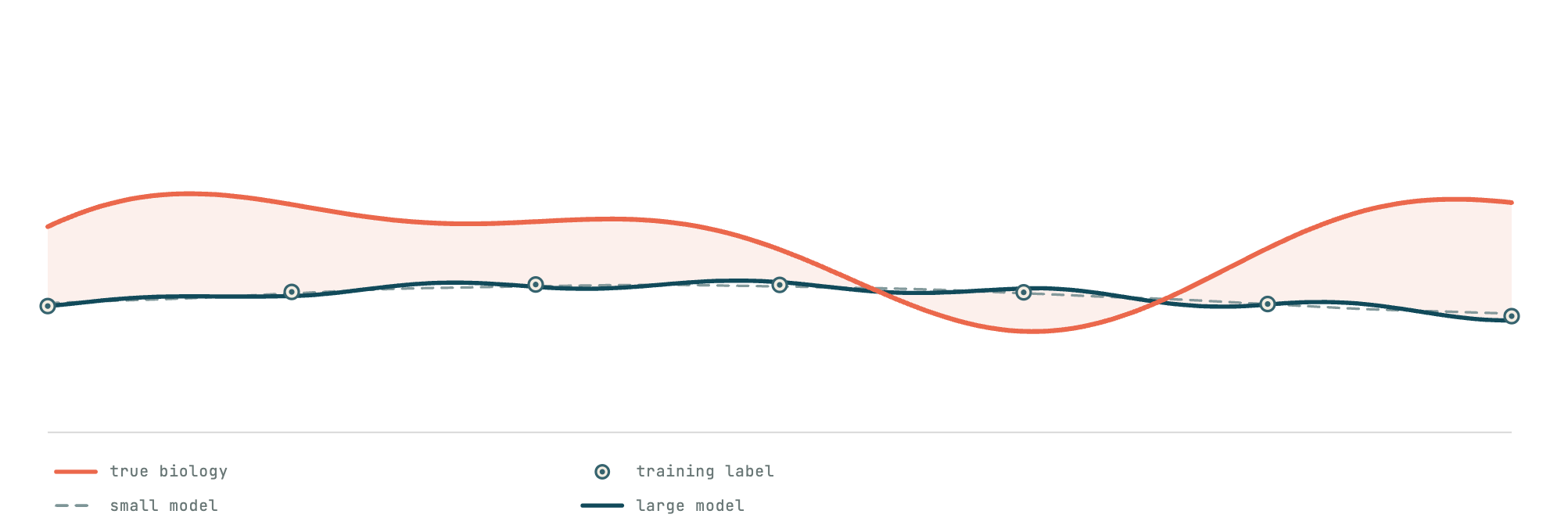
This is the trap the field walks into with remarkable consistency. A foundation model trained on clinical data at scale will learn powerful representations of the data's structure. But if the objective against which it is evaluated, fine-tuned, or deployed is the inherited label, then the representations are bent back toward the compression they should have been built to see past. Scale does not correct the objective. It amplifies it. The result is a system that can be simultaneously impressive in its generality and blind to the very thing it was built to measure, because it has learned with great fidelity to reproduce a convention rather than to interrogate it.
Our inversion
Often when people apply ML to healthcare, they mistake tractability for validity. Regressing a model onto an inherited score is straightforward: the label exists, the pipeline is known, the benchmarks are defined. It is a well-lit path, and it leads to the wrong destination. Learning the structure of the biology independently of the label, building representations from the signal upward rather than from the category down, is genuinely hard. It requires measurement systems that can see the signal before consulting the score, and the mathematical infrastructure to make what they see traceable, interpretable, and rigorous. That difficulty is met only with better mathematics, applied with care, at the level of the signal itself. This is where durable value is created, and it is where we have chosen to work.
So we invert the order: measurement precedes classification. Self-supervised learning on physiological signals, where the objective is the structure of the data rather than an external target. Regularisation that preserves the properties temporal biology actually exhibits. Subgroup identification that resolves population structure from the signal rather than from the diagnostic code. Treatment of missingness as informative rather than as inconvenient absence. These compose into a measurement stack designed to let the biology speak before the label is consulted. Labels become what they should always have been: weak, revisable queries applied to a representation, not the representation itself. When a label and the learned structure disagree, that disagreement is frequently the most important thing in the data. Internally we put it more plainly: we let the data speak for itself.
What this surfaces
What this makes visible is not available to a system trained to reproduce its labels. In Parkinson's, the UPDRS compresses a rich, continuous motor phenotype into a single score, and a model fit to that score learns the compression. But the kinematic structure of how a gait is actually changing, which joints are losing coordination, whether movement variability is rising in ways that precede clinical deterioration by months, is present in the data and measurable without the label. These precursors live in the continuous record a periodic, categorical evaluation never sees. Their absence is not random: the earliest signal is the smallest, and the smallest signal is precisely what such an assessment is least able to register, so the data most likely to be missing is the data that matters most. Reading that gap as carrying biology, rather than as data lost, is where precursor biomarkers are found. In psychiatry the stakes are sharper still. If the true structure of the data contains subgroups that cut across the inherited categories, defined by trajectory and physiology rather than by symptom checklist, they remain invisible to any system asked only to reproduce the diagnostic code. The biology may be organising itself along axes the nosology does not recognise, and without a measurement layer that can see those axes independently, they stay hidden.
Better measurement does not improve one thing. It improves everything downstream: earlier detection, smaller trials, subgroup identification, continuous monitoring, measures of biological change that resolve what categorical instruments cannot. These are all consequences of the same underlying capability, applied across diseases, data modalities, and scales.
None of this discards the validated endpoint. The qualified scale is what regulators accept and what gets a therapy approved, and a measurement that means to stand beside it must earn that standing through the same evidentiary path. The aim is not to discard the instrument the clinician trusts but to give them a better one, and to earn its place rather than assert it.
That patient has a body generating signals continuously: in how he moves, how he breathes, how his voice modulates, how his gait varies from step to step. The signal carries the biology. The question for anyone building in this field is whether they are constructing systems that measure it, or systems that have learned, with ever greater precision, to reproduce a century of compression. We have chosen the harder of the two, because it is the only one that reaches the ground truth at all.
Please cite this work as:
TimeTrace Labs. Ground Truth. TimeTrace Labs Blog, April 2026.
BibTeX:
@article{timetrace2026groundtruth,
author = {{TimeTrace Labs}},
title = {Ground Truth},
journal = {TimeTrace Labs Blog},
year = {2026},
url = {https://www.timetracelabs.com/blog/ground-truth}
}