Forma: Subgroup Identification in Population Psychiatry
In collaboration with Fondation FondaMental, we have been applying the mathematical layer of our measurement stack to a longitudinal psychiatry cohort for modelling symptom trajectories in schizophrenia. The dataset is large, prospective, and multisite. Symptoms were assessed at regular intervals over five years using a number of standardised psychiatric rating scales which aim to capture the severity of symptoms in schizophrenia and other psychotic conditions.
In a psychiatric population where heterogeneity in symptom presentation, illness course, and treatment history is the norm, assuming a single trajectory is unlikely to reflect the underlying reality. The clinical question is deceptively simple. Do all individuals follow the same path, or are there distinct (latent) subgroups with fundamentally different trajectories?
Getting these questions right is what allows genuine signal to be distinguished from the noise introduced by heterogeneity, attrition, and measurement.
Before asking whether latent subgroups exist, we first investigate how symptom burden across the entire population shifts over time — whether that shift is linear or whether it accelerates, decelerates, or curves. These are not preliminary formalities. They are load-bearing assumptions. Get them wrong and everything built on top of them inherits the error.
Only once those foundations are established does the harder question become tractable: not whether change happens, but whether it happens the same way for everyone. Selecting the number of latent subgroups is where the method earns its credibility — or loses it. Fit a model with too few classes and you collapse real heterogeneity into a single average that represents nobody well. Fit too many and you are carving noise into shapes, finding structure that will not replicate.
The selection process is empirical but not automatic. A sequence of models is estimated — one class, two classes, three, and so on — and each is evaluated against a set of criteria that collectively ask: does adding another class meaningfully improve the fit, and is the improvement worth the cost in complexity? No single criterion gives the answer. The decision is a judgment — informed by statistics, constrained by interpretability, and ultimately accountable to whether the classes make sense in the context of what is already known about the population.
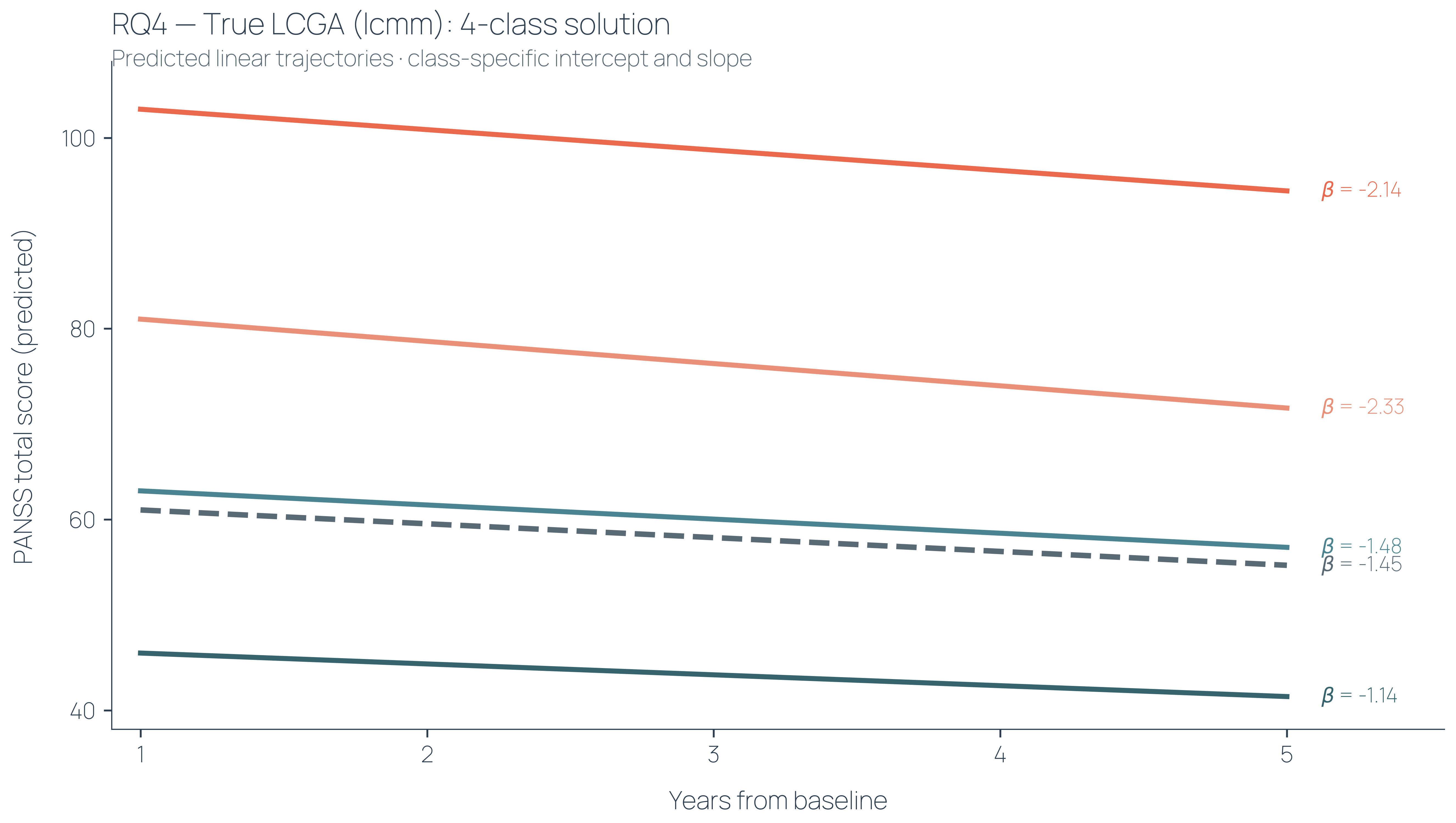
Applied to the Fondation FondaMental data, our model resolves the population into four distinct trajectory classes (left figure). The classes are labelled based on inspecting two things: where each class starts, and how it moves. Baseline severity and slope. In this case, the subgroups are distinguished primarily by where patients begin. The slopes are similar across groups — everyone moves at roughly the same rate, but what separates an individual in the highest class from one in the lowest is not the trajectory of their illness but their starting severity. Heterogeneity here is vertical, not longitudinal.
|
|

|
|
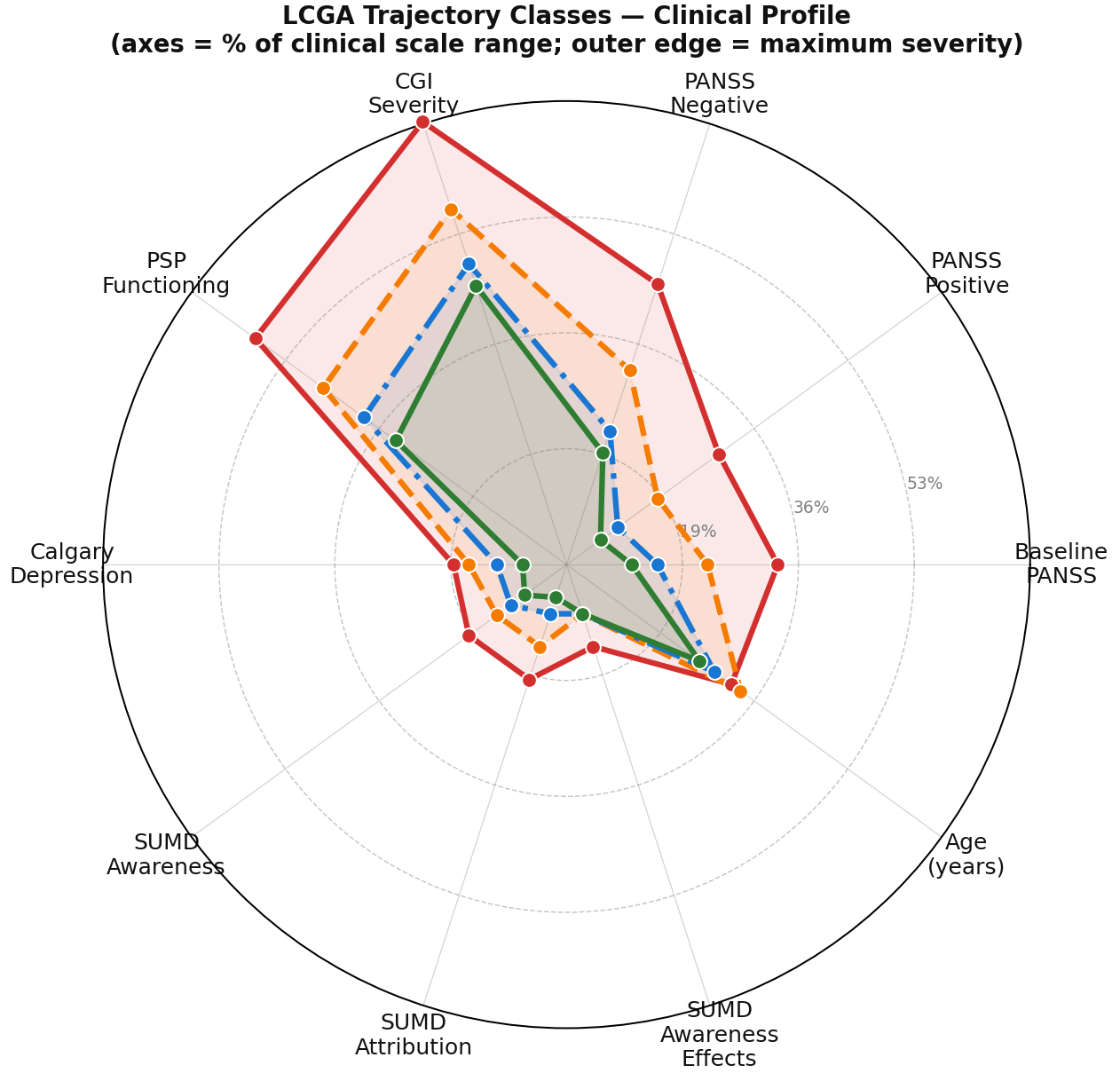
For a trajectory class to be clinically meaningful it needs to be recognisable — it needs to correspond to something a clinician would see and understand. The radar plot (right figure) is where that test happens. Each axis of the radar plot represents a clinical characteristic measured at baseline — symptom dimensions, functioning, cognitive profile, illness history, etc. Each class traces its own shape across those axes. Where the shapes diverge, the classes are telling you something. Where they converge, they are not.
In this solution, the separation is clinically coherent. The higher severity classes also sit highest on baseline markers of illness severity, functional impairment, and chronicity — variables that played no part in forming the classes The ordering holds across the whole profile, with the classes keeping their rank from one axis to the next rather than reshuffling.This is not noise. This is structure. And structure that aligns with clinical reality is what separates a meaningful solution from one that merely fits the data.
This work sits in the mathematical layers of the platform. No deep learning was required. This is one of the advantages of owning the full stack. The mathematical layer produces results even from smaller datasets, under sparsity and irregular sampling, with outputs that are interpretable and traceable by design. It does not require learned representations the data cannot yet support.
From here, the stack continues upward. Subgroup structure can forecast an individual's likely course — a patient in a high-severity, persistent class is more likely to have poor functioning years later — and baseline features can predict which class a patient belongs to at entry, turning the subgroups into a tool for early risk stratification. The infrastructure is designed so that what is established cleanly at the mathematical level can be built upon with confidence at every layer above it.
We are grateful to Fondation FondaMental for the collaboration and for the quality of their data and expertise. Our partnership with them continues.
Please cite this work as:
TimeTrace Labs. Forma: Subgroup Identification in Population Psychiatry. TimeTrace Labs Blog, May 2026.
BibTeX:
@article{timetrace2026forma,
author = {{TimeTrace Labs}},
title = {Forma: Subgroup Identification in Population Psychiatry},
journal = {TimeTrace Labs Blog},
year = {2026},
url = {https://www.timetracelabs.com/blog/forma}
}